![[AML Defence][2018 ICLR] Defense-GAN 논문 리뷰](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FbDYzgR%2Fbtq1m6ffNBG%2FAAAAAAAAAAAAAAAAAAAAADWMTCFLPI5Ra9LpUhMyKMlUprpA4vPt-RRk3yj2Pow2%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1767193199%26allow_ip%3D%26allow_referer%3D%26signature%3DUj%252Fbsh%252BxKqQEdIWCIP2ISYdPzG8%253D)
* AML 분야에 대해서 어느 정도 알고 있다는 전제하에 작성되었으며 개념보다는 논문 내 방식 설명에 집중했습니다.
아직 배우는 단계기 때문에 정 아니다 싶거나 궁금한 점이 있다면 댓글로 첨언해주세요.
이번에 리뷰할 논문은 Defense-GAN:Protecting Classifiers against Adversarial Attacks using Generative Model.
AML Defense 분야의 논문이며 기존 딥러닝 모델인 GAN(Genarative Adversarial Neetwork)를 활용한 적대적 방어 기법이다.
본 논문의 기법을 본격적으로 설명하기에 앞서 필요한 전제 정보들을 먼저 알아보겠다. (적혀있는 내용을 중심으로 서술하였으며 추가로 찾아보았던 부분은 출처를 적어두었음.)
Q0. Adversarial Defense의 종류
현존하는 Adversarial Defense는 크게 Adversarial Training, Defense Distillation, Denosing. 이 세 종류로 구분할 수 있다.
- Adverarial Training : 기존 분류 모델이 공격에 취약하지 않도록 adversarial example을 기존의 학습 데이터에 포함하여 학습시키는 기법.
- Defensive Distillation : 분류 모델의 학습 절차를 수정하는 것으로 gradient magnitude를 보완하여 모델을 재학습하는 기법
- Denoising : 데이터를 분류하기 전, 입력 데이터로부터 adversarial noise를 제거하는 기법. (Defense-GAN은 이 종류에 해당된다.)
1, 2번에 해당하는 방어기법은 특정 공격모델에 한해서만 대비가 가능하거나(Adversarial Training), 모델을 재학습해야하기 때문에 white-box Attack, black-box Attack 둘 중 하나에 특화되어 있다는 문제점이 있었다.
해당 논문에서는 존재하는 공격모델에 특화된 방어가 아니라 새로운 공격에 대해서 광범위하게 방어할 수 있는 기법을 추구하고 있기 때문에 3번째 기법인 Denoising 방식을 사용한다.
Q1. Defense-GAN은 왜 Denoising 방식을 추구했을까?
본 논문에서 설명하는 Denoising의 장점은 이러하다.
- 별도로 분류 모델의 구조를 변경하거나 학습 과정을 수정할 필요가 없어 접근이 용이하고 모델의 성능에 영향을 미치지 않는다. 단지 분류과정을 거치기 전, 입력 데이터의 전처리 과정으로 넣어주기만 하면 됨. (재학습할 필요도 없음!)
- 공격 모델에 특정되어 있지 않기 때문에 새로운 공격 유형 또한 범용적으로 방어할 수 있으며 white-box, black-box 구분할 것 없이 모든 종류의 공격 유형에 효율적이다.
Q2. 기존의 Denoising 기법, MagNet과의 차별점은 무엇일까?
그렇다면 Defense-GAN이 최초의 Denoising 기법이자 딥러닝의 Generative Model을 사용한 기법이냐고 묻는다면 그건 또 아니다.
Defense-GAN 이전에 가장 대표적인 Denoising 기법은 2017년도에 소개된 MagNet(Meng & Chen et al)이 있다.
분류 모델 앞의 전처리 과정에 해당하고, 이를 Generative Model을 사용하여 Adversarial Noise를 제거한다. MagNet과 Defense-GAN의 동작 과정을 비교해보면 주요 접근 방식이 거의 동일하다는 걸 알 수 있다.
본 논문에서도 자신들의 접근 방식과 가장 근접하다고 인정을 하고 있으며 아래 두 논점을 토대로 차별을 두었다고 밝힌다.
- Defense-GAN은 MagNet의 auto-encoder가 아닌 GAN을 사용한다.
- Defense-GAN은 별도로 global optimum한 값을 찾기 위해 여러 번 새로운 지점에서 시작하고, 초기화하는 방법(Initialization 과정에 해당함) 을 추가했다.
참고로 4장에서 두 기법의 성능을 비교했는데 Defense-GAN이 월등히 좋은 성능을 보였으니 위의 두 차별점을 통해 많은 개선을 했다고 보아도 무방할 것 같다.
Defense-GAN Approach
1. Training time
Defense-GAN의 학습 과정 자체는 크게 다른 점이 없다. 데이터를 추가한다던가 모델 구조 변형할 필요 없이 GAN의 Generative Model과, Classifier Model은 기존의 학습 데이터(ex. MNIST 또는 F-MNIST 등등)만을 가지고 평범하게 학습하면 된다. 분류 모델도 GAN도 충분히 학습되어 있는 모델이 있다면 변경할 필요 없이 그대로 가져오는 것도 상관없다.
2. Inference time
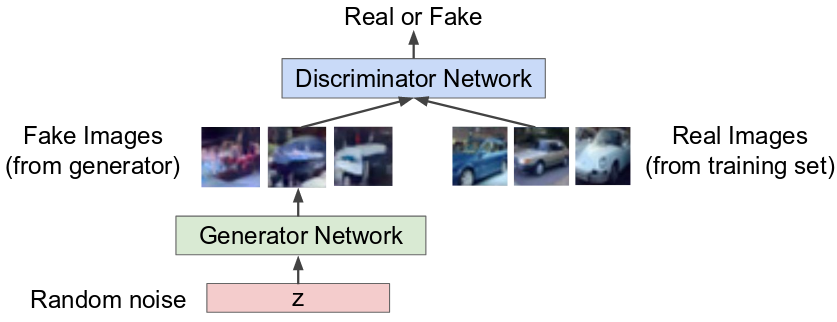
Defense-GAN이 실질적으로 동작하는 단계는 추론 단계다. Defense-GAN은 기존의 분류 모델의 전처리 과정에 GAN을 붙이는 구조로 동작 과정은 크게 Initialization, Generation, Classification으로 구분된다. Initialization과 Generation 단계는 입력 이미지와 가장 유사한 이미지를 만들어내는 과정이며, 이 단계를 거쳐 만들어지는 이미지를 분류 모델에 입력하게 된다.

Q3. GAN에서 생성된 이미지를 기존 이미지 대신에 입력해도 성능에 문제는 없을까?
사실상 Defense-GAN에서는 Input Image x를 입력값에 넣지 않는다. 대신에 G(z)로 생성되는 이미지를 입력한다. 즉, 생김새만 닮은 완전히 새로운 이미지라는 의미.
그렇다면 GAN 생성 이미지 때문에 오히려 오분류를 발생하지는 않을까?
분류 모델의 성능에 문제는 없고? 제대로 Denoising 효과를 줄 수 있는가?
이러한 질문거리가 생길 수도 있다. 친절하게도 본 논문에서는 왜 GAN에서 생성된 이미지가 기존 이미지를 대체 가능한지 증명하고 있다. 본론에 들어가기 위해서는 GAN의 손실함수에 대한 간단한 이해가 필요하다.
GANs, Generative Adversarial Networks.
GAN은 Generative 모델(통칭 G모델) 과 Discriminative 모델(통칭 D모델), 두 모델이 경쟁하는 구도로 이루어져 있다. D 모델은 '실제 이미지'와 'G모델에 의해 생성된 이미지'를 구분하도록 학습하며 그와 반대로 G 모델은 D모델이 구분하지 못하는 거짓 이미지를 생성하도록 학습한다.
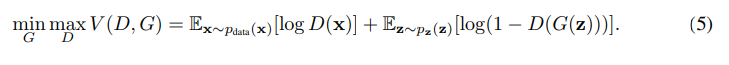
해당 이론은 MinMax game을 손실함수에 수학적으로 적용하여 구현되었다. D(x)는 D(fake image) = 0이 되도록 학습한다면, D(G(x))는 반대로 D(fake image)가 1이 되도록 학습한다. (물론 이론의 log(1−D(G(z)))를 최소화하는 연산은 시간이 오래 걸리기 때문에 log(D(g(x)))를 최대화하는 방향으로 연산을 진행한다.)
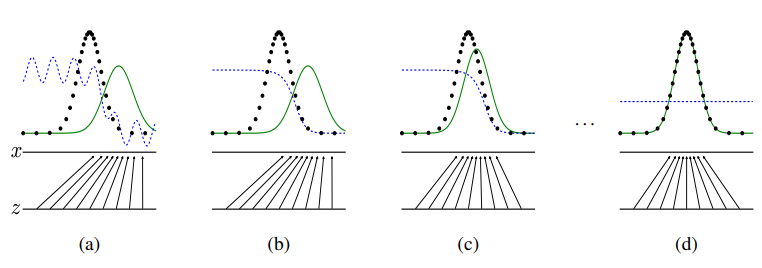
학습 시작 전 data distribution (Pd)와 generative distribution(Pg)는 (a)와 같이 다른 분포도를 보이지만 학습을 시작하면 할수록 Pd=Pg로 분포도가 동일해진다. discriminitive distribution은 더 이상 둘의 차이를 구분하지 못해 D(x)=1/2, 그래프와 같이 평행한 상태가 되고 학습이 종료된다.
본론으로 돌아가자면,
사실 본 논문에서는 GAN에서 나타나는 Mode Collapsing(분류할 클래스가 여러 개일 때, 생성자가 주어진 입력을 한 클래스에만 치우쳐서 변환되는 문제) 문제점을 개선한 WGAN(Wassertein GAN)을 사용하며 실제로 사용한 loss 함수식은 아래 식과 같다.

G모델은 충분히 학습되었을 때 Pg=Pd에 수렴한다는 사실은 마찬가지로 Defense-GAN에서 x값과 가장 유사하도록 도출된 G(z)와 x값의 차가 0에 수렴한다는 의미와 같다. 즉 분류 모델 입장에서는 G(z)와 x를 구분할 수 없으며 성능에 큰 차이가 생기지 않는다.
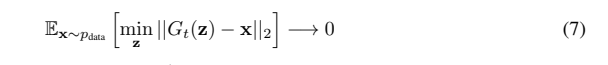
오히려 일반적인 학습 데이터로만 학습을 시켰기 때문에 만일 입력 이미지 x가 adversarial example이었을 경우, 학습한 적 없는 노이즈를 제외한 이미지를 생성하여 노이즈를 줄이는 denoising 효과를 주게 된다.
해당 접근방식이 효과가 있다는 걸 알았으니 GAN을 어떻게 활용했는지 동작과정을 살펴보겠다.
Q4. Initialization, Generation 의 동작과정 : 어떻게 입력 이미지와 가장 유사한 이미지를 생성할까?
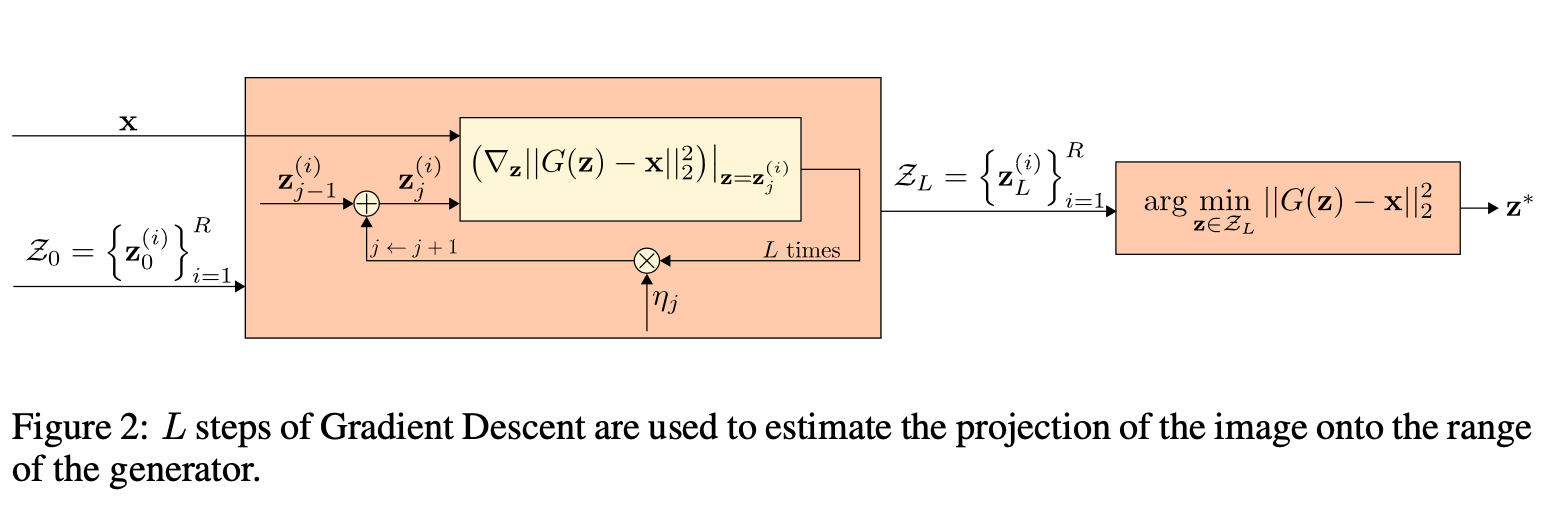
Generative 모델은 이미지를 생성하지만 x와 유사한 이미지를 생성하는 것은 별개의 문제다.
z는 랜덤 벡터로 이 벡터 값에 따라 G모델은 x와 동일한 클래스의 이미지를 생성할 수도 있고 다른 클래스의 이미지를 생성할 수도 있다. Defense-GAN 입장에서는 x와 유사한 이미지가 되도록 하는 z*를 찾는 것이 관건. 본 논문에서는 이를 G(z)와 x 사이의 거리가 최소값이 되도록 L번 동안 GD(gradient descent)를 수행하는 것으로 해결했다.
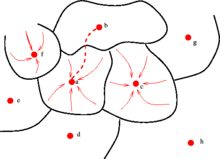
물론 이 과정만으로는 z*을 찾기는 힘들다. 아래 이미지와 같이 클래스는 여러 개. G(z)의 손실함수는 non-convex한 환경을 지닌다. 즉, local optimum값을 구할지 global optimum값을 구할지는 처음 z의 값, 시작 위치에 따라 달라지게 되는데 L번의 GD는 시작 위치에는 기여하는 바가 없다. 본 논문에서는 R번 z를 새로 생성하여 random start하는 것으로 최적의 z*을 구했다.
적절한 L과 R의 횟수
4.1.1 장에서는 L과 R의 값을 몇으로 설정하는 것이 좋을지 실험을 진행했다.
L의 경우, adversarial example을 입력값으로 사용한 상태에서 특정 횟수가 넘으면 오버피팅되어 노이즈까지 유사하게 만들어내어 오히려 오분류가 되는 실험 결과를 보였고(좌) R의 경우, R의 횟수가 증가하면 할수록 global optimum을 찾아낼 확률이 높아지므로 정확도가 높아지는 실험 결과를 보였다.(우)

Experiments
실험 결과는 두드러지는 점만을 작성하고 넘어가겠다. 본 논문에서는 Defense-GAN의 성능을 검증하기 위해 black-box attack에서는 FGSM, white-box attack에서는 Magnet, FGSM, Rand+FGSM, CW를 중심으로 실험했으며 이미지 셋은 MNIST, F-MNIST를 사용했다.
Defense-GAN은 유사 구조를 가진 MagNet보다 높은 정확도를 보여주었고. FGSM을 통한 adversarial training defense보다는 정확도가 낮긴 하나 해당 방어는 오직 FGSM에만 대항한다는 점에서 시사점이 있음을 어필한다. 또한 GAN의 non-linear한 구조 때문에 white-box attack에도 다소 굳건한 모습을 보임을 실험을 통해 드러냈다.
Limitation
Defense-GAN의 방어 성공 여부는 GAN의 expressiveness와 generative power에 의존하므로 GAN의 단점은 고스란히 Defense-GAN의 단점이 된다. GAN은 적절히 학습과 튜닝이 되어있지 않을 경우 제대로 된 성능을 발휘하지 못해 사용 시 까다로운 요소가 될 수 있다.
또한 hyper-parameter인 L과 R의 횟수는 성능에 큰 영향을 끼친다. 이는 공격에 대해 아무런 지식 없이는 적절히 튜닝이 될 수 없다는 의미. 결국 Defense-GAN 또한 완전히 공격에 독립적이지는 않았다.
'논문 스터디 > ML attack' 카테고리의 다른 글
| [2020 EMNLP, NLP black-box attack] BERT-Attack Adversarial Attack Against BERT Using BERT (0) | 2023.06.03 |
|---|---|
| [AAAI 2020, NLP black-box attack] TextFooler (1) | 2023.05.16 |
| [2017 NIPS] Attention is All You Need 리뷰 (1) | 2022.10.04 |
| [XAI] CAM과 Grad-CAM 논문 리뷰 (0) | 2022.01.30 |
| [AML Defence][2019 CVPR] Feature Denoising for Improving Adversarial Robustness 논문 리뷰 (0) | 2021.08.22 |