
sweep… .. 이녀석은.. 하이퍼 파라미터를 조정하는데 있어 최고의 도구다. 그동안 직접 손으로 돌렸다는 사실이 한탄스러울 정도. 다들 꼭 한번씩 쓰고 필자처럼 광명을 찾길 바라며…
기존 wandb sweep을 사용하는 튜토리얼은 jupyter notebook 기반으로 구성되어 있다. [튜토리얼 링크]
Organizing_Hyperparameter_Sweeps_in_PyTorch_with_W&B.ipynb
Run, share, and edit Python notebooks
colab.research.google.com

하지만… 필자는 jupyter notebook은 왠지 손맛(?)이 느껴지지 않아서 그런지 command line으로 스크립트를 실행하고 싶었는데.. 위의 튜토리얼에서는 command line에서 실행할 경우 yaml로 config 파일을 만들어 실행하라고 표기되어있다. 필자는.. yaml 을 읽어오는 코드까지 작성할 필요는 느끼지 못하였기에.. yaml 파일을 만들지 않고도 sweep을 실행하는 방법을 소개하고자 한다. 뭐.. 모르겠다면 위의 튜토리얼 링크에서 상냥하게 소개해주고 있으니 다시 한번 살펴보시고.
먼저 sweep은 wandb에 속해있는 기능이므로 wandb를 먼저 설치해주어야 한다. 기존에 작성하였던 wandb 사용하기 글을 따라 설치하고 코드를 몇줄 작성해주자.
wandb가 작동한다면 두 번째로 해야할 것은 sweep configuration 작성. 본 글에서는 가장 간단하게 실행하는 방법만을 소개하고자 코드 안에 config를 dict 타입으로 넣어버렸다. sweep을 실행할 코드에 다음과 같은 dict를 만들어 넣어주면 끝.
이 때, parameters안에 들어있는 ‘epochs’와 ‘seed’는 a.epochs와 같이 config의 속성을 의미하니 맞추어 넣어주면 될 것 같다. method에는 모든 경우의 수를 모두 사용하여보는 grid search와 무작위를 의미하는 random, 확률적으로 하이퍼파라미터를 조합하는 bayes 방법이 있다. 취향껏 설치해주자. 필자는.. random이나 bayesian 을 주로 사용하긴 한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
sweep_configuration = {
'method': 'random',
'metric': {'goal': 'minimize', 'name': 'loss'},
'parameters':
{
'epochs': {'value': 3},
'seed': {'value': 3241},
'lr': {
'distribution': 'uniform',
'min': 1e-6,
'max': 1e-3
},
'batch_size': {'values': 64, 128, 256},
}
}
|
cs |
그러고 나면 남은 것은 sweep을 실행하면 바로 확인 할 수 있다. 필자는 sweep 함수를 따로 만들어주었다.
|
1
2
3
4
|
def sweep():
import wandb
sweep_id = wandb.sweep(sweep=sweep_configuration, project="demo")
wandb.agent(sweep_id, train_sweep, count=10)
|
cs |
앞서 작성한 sweep_configuration을 인자로 넣어 sweep_id를 생성하였으며 이를 wandb.agent를 통해 실행한다. 이때, agent는 각 경우의 수에 따라 실행하는 객체를 agent라고 하고 각 경우의 수를 만들어 실행시키는 것을 sweep controller라고 하는 듯 하다. 직관적으로 sweep이 작동하는 방식은 [그림 2]를 통해 이해하도록 하자.
이 agent를 통해 train 함수를 실행시키는 것으로 sweep 실행이 가능하다. 이 때, 주의할 점은 wandb.agent의 첫번째 인자인 sweep_id가 train함수의 config인자로 들어가게 된다는 것이다. 대충.. train 함수를 구성할 때는 다음과 같이 config 인자 하나만 갖도록 구성하면 사용 가능하다.
|
1
2
3
4
5
6
7
8
|
def train_sweep(config=None):
import wandb
with wandb.init(config=config):
config = wandb.config
data_iter = DataLoader(dataset, batch_size=config.batch_size, shuffle=True, validation_split=0.1, num_workers=8, pin_memory=True)
model = Model(config)
trainer = Trainer(config, model..)
trainer.train()
|
cs |
또한 wandb.agent(sweep_id, train_sweep, count=10) 의 count는 몇번 실행할지를 의미한다. 해당 코드는 10개의 하이퍼파라미터 조합만을 테스트한다는 뜻. 잘 조정하여 테스트해보길 바란다.
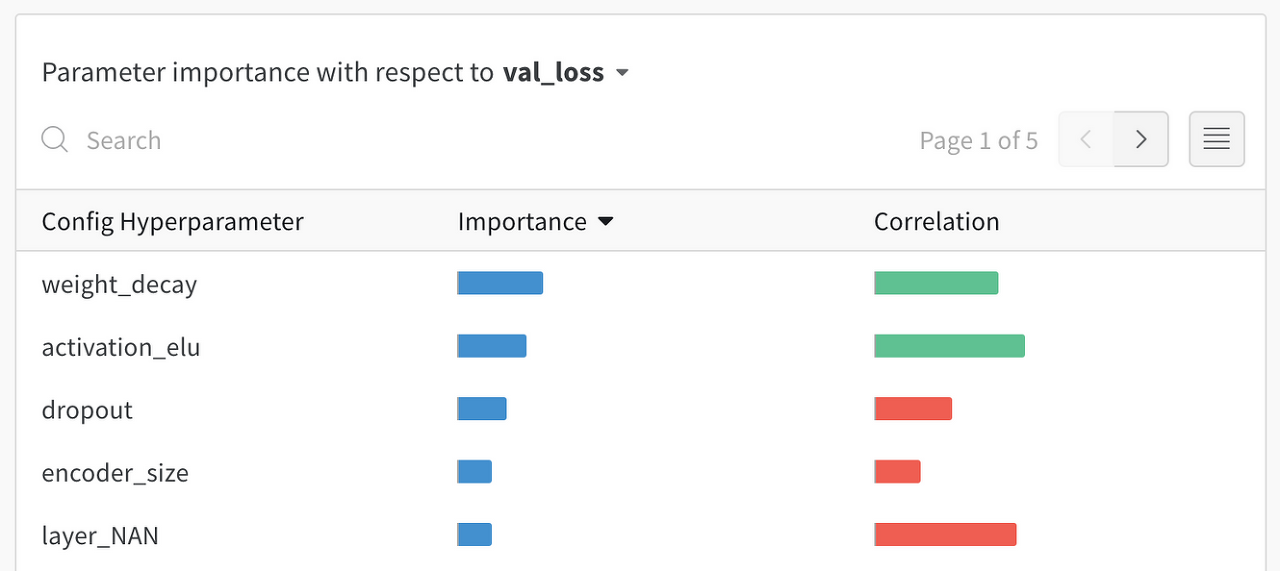
그렇게 sweep을 실행이 끝나게 되면 이렇게..[그림 3]과 [그림 4]와 같이 실험한 여러 조합이 어떤 성능을 지니는지 시각화해서 표현을 해주며 어떤 파라미터가 목표에 영향을 주는지까지 분석해준다. … …. 처음 필자가 시도해보고…. 와.. 정말 놀랐다. 이렇게 좋은 툴이 있다니.. 신세계였다..

'Setting Tips' 카테고리의 다른 글
| update-alternatives (0) | 2023.04.05 |
|---|---|
| psutil 사용해서 특정 cpu에 python 스크립트 할당하기 (0) | 2023.03.28 |
| wandb 사용하기 (0) | 2022.11.16 |
| 맥 터미널 내 code 명령어로 vs code 여는 방법 (0) | 2022.09.26 |
| 그래픽카드 변경으로 인한 pytorch, CUDA 버전 비매칭 이슈 해결하기 (0) | 2022.05.22 |